This class provides a nonlinear conjugate-gradient optimizer. More...
#include <conjugate_gradient.h>
Public Member Functions | |
| template<class Func , class Deriv > | |
| ConjugateGradient (const Vector< Size > &start, const Func &func, const Deriv &deriv) | |
| template<class Func > | |
| ConjugateGradient (const Vector< Size > &start, const Func &func, const Vector< Size > &deriv) | |
| void | init (const Vector< Size > &start, const Precision &func, const Vector< Size > &deriv) |
| template<class Func > | |
| void | find_next_point (const Func &func) |
| bool | finished () |
| void | update_vectors_PR (const Vector< Size > &grad) |
| template<class Func , class Deriv > | |
| bool | iterate (const Func &func, const Deriv &deriv) |
Public Attributes | |
| const int | size |
| Vector< Size > | g |
| Vector< Size > | h |
| Vector< Size > | minus_h |
| Vector< Size > | old_g |
| Vector< Size > | old_h |
| Vector< Size > | x |
| Vector< Size > | old_x |
| Precision | y |
| Precision | old_y |
| Precision | tolerance |
| Precision | epsilon |
| int | max_iterations |
| Precision | bracket_initial_lambda |
| Precision | linesearch_tolerance |
| Precision | linesearch_epsilon |
| int | linesearch_max_iterations |
| Precision | bracket_epsilon |
| int | iterations |
Detailed Description
template<int Size = Dynamic, class Precision = double>
struct TooN::ConjugateGradient< Size, Precision >
This class provides a nonlinear conjugate-gradient optimizer.
The following code snippet will perform an optimization on the Rosenbrock Bananna function in two dimensions:
double Rosenbrock(const Vector<2>& v) { return sq(1 - v[0]) + 100 * sq(v[1] - sq(v[0])); } Vector<2> RosenbrockDerivatives(const Vector<2>& v) { double x = v[0]; double y = v[1]; Vector<2> ret; ret[0] = -2+2*x-400*(y-sq(x))*x; ret[1] = 200*y-200*sq(x); return ret; } int main() { ConjugateGradient<2> cg(makeVector(0,0), Rosenbrock, RosenbrockDerivatives); while(cg.iterate(Rosenbrock, RosenbrockDerivatives)) cout << "y_" << iteration << " = " << cg.y << endl; cout << "Optimal value: " << cg.y << endl; }
The chances are that you will want to read the documentation for ConjugateGradient::ConjugateGradient and ConjugateGradient::iterate.
Linesearch is currently performed using golden-section search and conjugate vector updates are performed using the Polak-Ribiere equations. There many tunable parameters, and the internals are readily accessible, so alternative termination conditions etc can easily be substituted. However, ususally these will not be necessary.
Constructor & Destructor Documentation
| ConjugateGradient | ( | const Vector< Size > & | start, |
| const Func & | func, | ||
| const Deriv & | deriv | ||
| ) |
Initialize the ConjugateGradient class with sensible values.
- Parameters:
-
start Starting point, x func Function f to compute 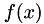
deriv Function to compute 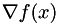
References ConjugateGradient< Size, Precision >::init().
| ConjugateGradient | ( | const Vector< Size > & | start, |
| const Func & | func, | ||
| const Vector< Size > & | deriv | ||
| ) |
Initialize the ConjugateGradient class with sensible values.
- Parameters:
-
start Starting point, x func Function f to compute deriv
References ConjugateGradient< Size, Precision >::init().
Member Function Documentation
Initialize the ConjugateGradient class with sensible values.
Used internally.
- Parameters:
-
start Starting point, x func deriv
References ConjugateGradient< Size, Precision >::bracket_epsilon, ConjugateGradient< Size, Precision >::bracket_initial_lambda, ConjugateGradient< Size, Precision >::epsilon, ConjugateGradient< Size, Precision >::g, ConjugateGradient< Size, Precision >::h, ConjugateGradient< Size, Precision >::iterations, ConjugateGradient< Size, Precision >::linesearch_epsilon, ConjugateGradient< Size, Precision >::linesearch_max_iterations, ConjugateGradient< Size, Precision >::linesearch_tolerance, ConjugateGradient< Size, Precision >::max_iterations, ConjugateGradient< Size, Precision >::minus_h, ConjugateGradient< Size, Precision >::old_y, ConjugateGradient< Size, Precision >::size, TooN::sqrt(), ConjugateGradient< Size, Precision >::tolerance, ConjugateGradient< Size, Precision >::x, and ConjugateGradient< Size, Precision >::y.
Referenced by ConjugateGradient< Size, Precision >::ConjugateGradient().
| void find_next_point | ( | const Func & | func | ) |
Perform a linesearch from the current point (x) along the current conjugate vector (h).
The linesearch does not make use of derivatives. You probably do not want to use this function. See iterate() instead. This function updates:
- x
- old_c
- y
- old_y
- iterations Note that the conjugate direction and gradient are not updated. If bracket_minimum_forward detects a local maximum, then essentially a zero sized step is taken.
- Parameters:
-
func Functor returning the function value at a given point.
References ConjugateGradient< Size, Precision >::bracket_epsilon, ConjugateGradient< Size, Precision >::bracket_initial_lambda, TooN::Internal::bracket_minimum_forward(), TooN::brent_line_search(), ConjugateGradient< Size, Precision >::h, ConjugateGradient< Size, Precision >::iterations, ConjugateGradient< Size, Precision >::linesearch_epsilon, ConjugateGradient< Size, Precision >::linesearch_max_iterations, ConjugateGradient< Size, Precision >::linesearch_tolerance, ConjugateGradient< Size, Precision >::minus_h, ConjugateGradient< Size, Precision >::old_x, ConjugateGradient< Size, Precision >::old_y, ConjugateGradient< Size, Precision >::x, and ConjugateGradient< Size, Precision >::y.
Referenced by ConjugateGradient< Size, Precision >::iterate().
| bool finished | ( | ) |
Check to see it iteration should stop.
You probably do not want to use this function. See iterate() instead. This function updates nothing.
References ConjugateGradient< Size, Precision >::epsilon, ConjugateGradient< Size, Precision >::iterations, ConjugateGradient< Size, Precision >::max_iterations, ConjugateGradient< Size, Precision >::old_y, ConjugateGradient< Size, Precision >::tolerance, and ConjugateGradient< Size, Precision >::y.
Referenced by ConjugateGradient< Size, Precision >::iterate().
| void update_vectors_PR | ( | const Vector< Size > & | grad | ) |
After an iteration, update the gradient and conjugate using the Polak-Ribiere equations.
This function updates:
- g
- old_g
- h
- old_h
- Parameters:
-
grad The derivatives of the function at x
References ConjugateGradient< Size, Precision >::g, ConjugateGradient< Size, Precision >::h, ConjugateGradient< Size, Precision >::minus_h, ConjugateGradient< Size, Precision >::old_g, and ConjugateGradient< Size, Precision >::old_h.
Referenced by ConjugateGradient< Size, Precision >::iterate().
| bool iterate | ( | const Func & | func, |
| const Deriv & | deriv | ||
| ) |
Use this function to iterate over the optimization.
Note that after iterate returns false, g, h, old_g and old_h will not have been updated. This function updates:
- x
- old_c
- y
- old_y
- iterations
- g*
- old_g*
- h*
- old_h* 'd variables not updated on the last iteration.
- Parameters:
-
func Functor returning the function value at a given point. deriv Functor to compute derivatives at the specified point.
- Returns:
- Whether to continue.
References ConjugateGradient< Size, Precision >::find_next_point(), ConjugateGradient< Size, Precision >::finished(), ConjugateGradient< Size, Precision >::update_vectors_PR(), and ConjugateGradient< Size, Precision >::x.
