Evaluation of useful functions. More...
Functions | |
| template<class F , int S, class P , class B > | |
| Vector< S, P > | numerical_gradient (const F &f, const Vector< S, P, B > &x) |
| template<class F , int S, class P , class B > | |
| Matrix< S, 2, P > | numerical_gradient_with_errors (const F &f, const Vector< S, P, B > &x) |
| template<class F , int S, class P , class B > | |
| pair< Matrix< S, S, P > , Matrix< S, S, P > > | numerical_hessian_with_errors (const F &f, const Vector< S, P, B > &x) |
| template<class F , int S, class P , class B > | |
| Matrix< S, S, P > | numerical_hessian (const F &f, const Vector< S, P, B > &x) |
Detailed Description
Evaluation of useful functions.
Function Documentation
Extrapolate a derivative to zero using Ridder's Algorithm.
Ridder's algorithm works by evaluating derivatives with smaller and smaller step sizes, fitting a polynomial and extrapolating its value to zero.
This algorithm is generally more accurate and much more reliable, but much slower than using simple finite differences. It is robust to awkward functions and does not require careful tuning of the step size, furthermore it provides an estimate of the errors. This implementation has been tuned for accuracy instead of speed. For an estimate of the errors, see also numerical_gradient_with_errors(). In general it is useful to know the errors since some functions are remarkably hard to differentiate numerically.
Neville's Algorithm can be used to find a point on a fitted polynomial at 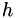 . Taking some points
. Taking some points 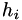 and
and 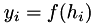 , one can define a table of points on various polyomials:
, one can define a table of points on various polyomials:
![\[ \begin{array}{ccccccc} h_0 & y_0 & P_0 & & & \\ & & & P_{01} & & \\ h_1 & y_1 & P_1 & & P_{012} & \\ & & & P_{12} & & P_{0123} \\ h_2 & y_2 & P_2 & & P_{123} & \\ & & & P_{23} & & \\ h_3 & y_3 & P_3 & & & \\ \end{array} \]](form_110.png)
where 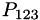 is the value of a polynomial fitted to datapoints 1, 2 and 3 evaluated at
is the value of a polynomial fitted to datapoints 1, 2 and 3 evaluated at 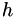 . The initial values are simple to evaluate:
. The initial values are simple to evaluate: 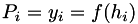 . The remaining values are determined by the recurrance:
. The remaining values are determined by the recurrance:
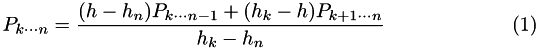
For Ridder's algorithm, we define the extrapolation point 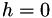 and the sequence of points to evaluate as
and the sequence of points to evaluate as 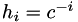 where
where 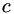 is some constant a little greater than 1. Substituting in to the above equation gives:
is some constant a little greater than 1. Substituting in to the above equation gives:
![\[ P_{k \cdots n} = \frac{c^{-k} P_{k+1 \cdots n} - P_{k \cdots n-1}}{c^{n - k} - 1} \]](form_118.png)
To measure errors, when computing (for example) 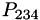 , we compare the value to the lower order with the same step size
, we compare the value to the lower order with the same step size 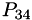 , and the lower order with a larger step size
, and the lower order with a larger step size 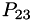 . The error estimate is the largest of these. The extrapolation with the smallest error is retained.
. The error estimate is the largest of these. The extrapolation with the smallest error is retained.
Not only that, but since every value of P is used, every single subset of points is used for polynomial fitting. So, bad points for large and small do not spoil the answer.
It is generally assumed that as decreases, the errors decrease, then increase again. Therefore, if the current step size did not yield any improvements on the best point so far, then we terminate when the highest order point is 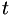 times worse then the previous order point.
times worse then the previous order point.
The parameters are:
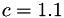
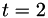
- Max iterations = 400
References
- Ridders, C. J. F, 1982, Advances in Engineering Software, 4(2) 75--76
- Press, Vetterling, Teukolsky, Flannery, Numerical, 1997, Numerical Recipies in C (2nd ed.), Chapter 5.7
- Parameters:
-
f Functor to differentiate x Point about which to differentiate.
References Vector< Size, Precision, Base >::size().
Compute numerical gradients with errors.
See numerical_gradient(). Gradients are returned in the first row of the returned matrix. Errors are returned in the second row. The errors have not been scaled, so they are in the same range as the gradients.
- Parameters:
-
f Functor to differentiate x Point about which to differentiate.
References Vector< Size, Precision, Base >::size().
| pair<Matrix<S, S, P>, Matrix<S, S, P> > TooN::numerical_hessian_with_errors | ( | const F & | f, |
| const Vector< S, P, B > & | x | ||
| ) |
Compute the numerical Hessian using central differences and Ridder's method:
![\[ \frac{\partial^2 f}{\partial x^2} \approx \frac{f(x-h) - 2f(x) + f(x+h)}{h^2} \]](form_125.png)
![\[ \frac{\partial^2 f}{\partial x\partial y} \approx \frac{f(x+h, y+h) - f(x-h,y+h) - f(x+h, y-h) + f(x-h, y-h)}{4h^2} \]](form_126.png)
See numerical_gradient().
- Parameters:
-
f Functor to double-differentiate x Point about which to double-differentiate.
References Vector< Size, Precision, Base >::size().
Compute the numerical Hessian and errors.
The Hessian is returned as the first element, and the errors as the second. See numerical_hessian().
- Parameters:
-
f Functor to double-differentiate x Point about which to double-differentiate.
References Vector< Size, Precision, Base >::size().
